Agent Gate: Execution Authority for AI Agents
An open-source policy enforcement layer that controls what AI agents do, not what they say. Built on nuclear command and control principles I applied during my service as Nuclear Strike Advisor to the President aboard the Looking Glass airborne command post.
GitHub Repository · Apache 2.0 · Python 3.9.
The Problem
AI agents are gaining the ability to act autonomously, deleting files, modifying configurations, writing to databases, executing system commands. The current guardrail ecosystem focuses almost entirely on what the LLM says: content safety, prompt injection detection, output filtering. Almost nobody is building the authority layer that controls what the agent does before it does it.
Existing approaches fall into two camps, and both fail:
"Trust the agent to manage its own safety." The agent backs up its own files before deletion. The problem: the agent can also delete the backups. The safety net is inside the blast radius.
"Block destructive actions entirely." This stalls the agent. The denial itself becomes the damage, you've built an expensive system that can't do the work you need it to do.
Agent Gate takes a third approach: make every action safe to allow.
The Insight
Every AI agent framework, Claude, OpenAI, LangChain, CrewAI, MCP, follows the same pattern:
Agent reasons → Agent outputs structured tool call (JSON) → Client code executesThe model never touches the world directly. It proposes a structured action. Client code receives that proposal and executes it. That gap between "proposed" and "executed" is the natural insertion point for authority control, and it already exists in every framework.
This is architecturally identical to how firewalls inspect packets: source, destination, protocol, matched against rules. The tool call is a structured, inspectable object. We don't need to understand the agent's reasoning. We need to see `rm important.txt` in a structured tool call and match it against policy.
The Nuclear C2 Analogy
My background as Nuclear Strike Advisor to the President aboard the Looking Glass, the airborne command post for U.S. Strategic Command, is directly relevant to this problem.
Nuclear weapons use Permissive Action Links (PALs). A PAL doesn't evaluate whether a launch is wise. It doesn't assess the reasoning behind the order. It verifies that correct authority codes are present and that the action falls within the authorized envelope. If the codes match, the weapon arms. If they don't, it doesn't. The evaluation is structural, not judgmental.
Agent Gate follows the same principle:
Don't evaluate the agent's reasoning. Verify the action's authorization.
The gate must not prevent authorized actions. A gate that's too restrictive is as dangerous as one that's too permissive.
The backup vault is like the safing mechanism. It doesn't prevent the action, it ensures the action is reversible.
This isn't a metaphor. It's the same design pattern applied to a different domain.
How It Works
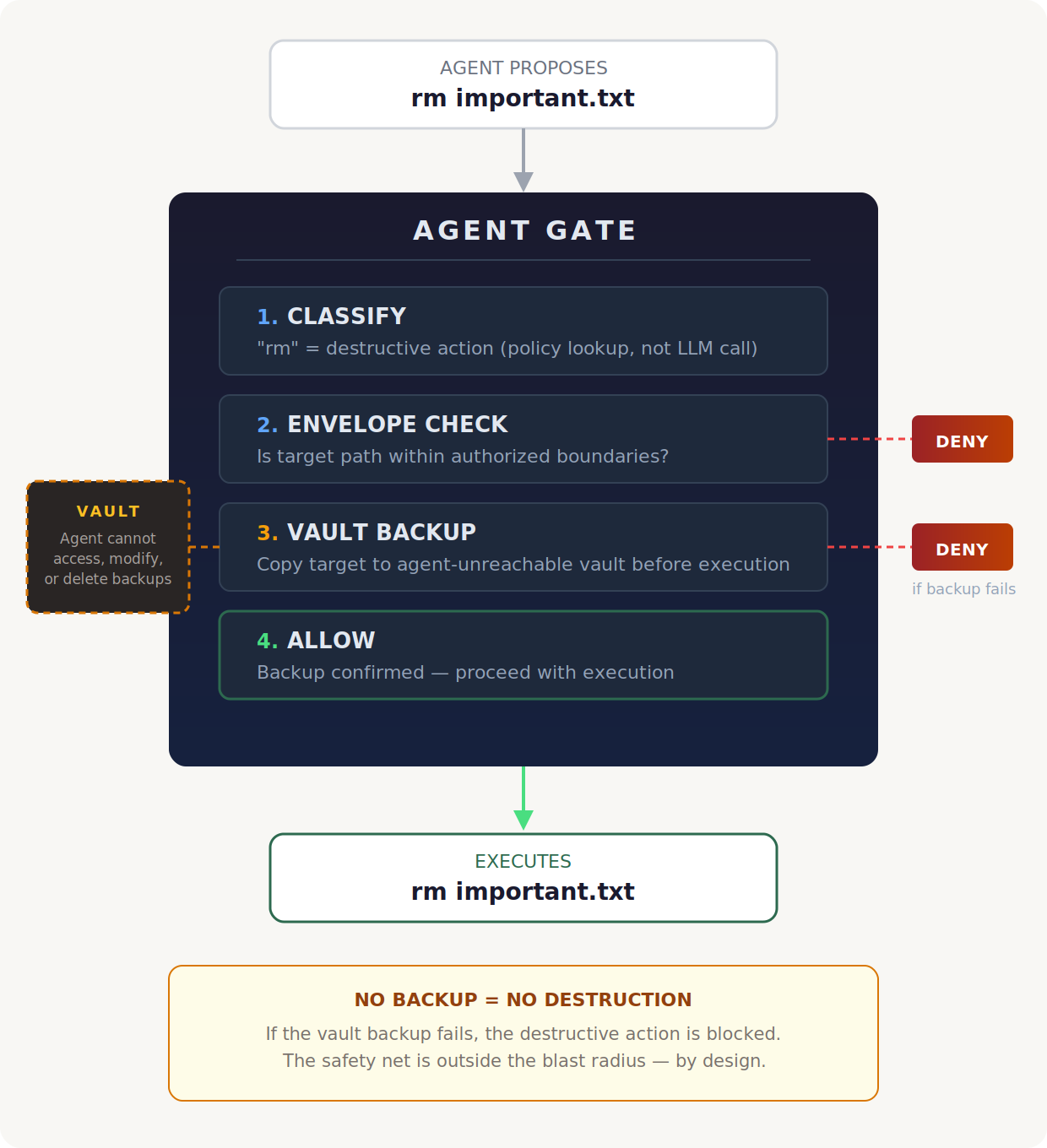
When an agent proposes a destructive action, the gate intercepts the structured tool call before anything executes.
First, it classifies the action against pre-computed policy. This is a lookup, not an LLM call, microseconds, not seconds. "rm" maps to the destructive tier. "cat" maps to read-only. "rm -rf /" maps to blocked.
Next, the gate checks whether the target path falls within the agent's authorized envelope. Any path outside the boundary is a hard deny, with an explanation of what was violated and what would be needed to proceed.
For destructive actions within the envelope, the gate copies every target file to a vault before execution. The vault lives outside the agent's permitted directories. The same gate that enforces the envelope protects the vault, the agent cannot access, modify, or delete its own backups.
Only after the backup is confirmed does the action proceed. If the backup fails, the action is blocked. No snapshot, no destruction.
The agent runs at full speed and full autonomy. It doesn't know the gate is there. But every destructive action is now reversible, and the recovery path is entirely in human hands.
Tiered Classification
Every action an agent can propose maps to one of four tiers, and the mapping is defined at design time, not evaluated at runtime. When the gate sees a tool call, it matches the command against policy. The classification is a lookup table, not a judgment call.
Read-only actions flow through instantly. There's nothing to protect against, so there's no overhead. The gate confirms the target is within the envelope and gets out of the way.
Destructive actions are where the vault earns its keep. Before a deletion, a move, or an overwrite executes, the gate snapshots every target file. The action only proceeds after the backup is confirmed. Policy conditions add nuance, writing a brand new file isn't destructive because there's nothing to destroy, but overwriting an existing file triggers the vault automatically.
Blocked actions are a hard stop. No vault, no escalation path within the current policy. The gate returns a structured explanation: what was blocked, why, and what policy change would be needed to allow it.
Anything the policy doesn't recognize defaults to deny. The gate doesn't guess at intent or risk, it stops and surfaces the decision to a human. Unknown commands require a policy update or explicit approval before they can run.
Policy as Code
The entire authority model is a single YAML file. You define the rules once at design time, which directories the agent can touch, what commands trigger a backup, what commands are prohibited outright, and the gate enforces them at runtime without any further configuration.
The envelope section draws the boundary. Allowed paths define where the agent can operate. Denied paths carve out exclusions — SSH keys, AWS credentials, and critically, the vault itself. Variables like ${WORKDIR} and ${HOME} resolve when the policy loads, so the same policy file works across environments without hardcoded paths.
The vault section sets the safety contract. The most important line is a single key-value pair: on_failure set to deny. That one declaration is the foundation of the entire system. If the backup can't be created, the destructive action doesn't execute. Period.
The actions section maps commands to tiers. But it's not just a flat list, policy conditions add precision. A write_file command is only classified as destructive when the condition target_exists is true, meaning the file already exists and would be overwritten. Writing a new file has nothing to destroy, so it flows through without vault overhead. The same logic applies to cp - copying to a new location is safe, copying over an existing file triggers a backup first.
The result is a policy that's readable by a human, auditable by compliance, and enforced by machine, all from the same source file.
Live Integration: Claude Code
Agent Gate isn't a design document, it's running in production against Anthropic's Claude Code. The integration uses Claude Code's PreToolUse hooks system, which fires an event before every tool execution. The hook receives the tool name and input as JSON on stdin, passes it to the gate, and maps the verdict back to an exit code: zero to allow, two to block.
The hooks themselves are roughly sixty lines each, thin adapters that translate Claude Code's format into the core library's tool call structure. All classification, envelope enforcement, vault logic, and condition evaluation lives in the core library as a single source of truth. Nothing is duplicated in the integration layer.
The result is that Claude Code runs at full speed with dangerous permissions enabled while the gate silently enforces policy underneath. Claude doesn't know the gate exists. It proposes actions, the gate intercepts them, and allowed actions execute with no visible delay. Denied actions return structured feedback explaining what was blocked, why, and what would be needed to proceed.
Every scenario we threw at it worked as designed. File deletions triggered vault backups before execution. Recursive directory deletions backed up every file in the tree. Overwrites of the same file created separate timestamped snapshots, full point-in-time recovery. Attempts to operate outside the envelope or touch the vault were hard-denied with clear explanations. Compound bash commands were decomposed and each sub-command gated independently. Twenty-two tests passing with coverage across all tiers, conditions, vault integrity, and denial feedback quality.
Vault Architecture
The vault is what makes full agent autonomy possible. Every destructive action, every deletion, every overwrite, every in-place edit, creates a timestamped snapshot before execution. The snapshot includes the file contents, a SHA-256 hash for integrity verification, the file size, and which action triggered the backup. All of this is recorded in a JSONL manifest that serves as a complete audit trail.
The critical design choice is where the vault lives. It sits outside the agent's permitted directory envelope, and the same gate that enforces that envelope protects the vault. The agent literally cannot reach the backups, not to read them, not to modify them, not to delete them. The safety net is outside the blast radius.
Snapshots are organized by a hash of the original file path, so every version of the same file is grouped together. Overwrite a file three times, and you get three separate snapshots with three different timestamps, full point-in-time recovery to any version. Retention policy limits keep the vault from growing unbounded: a configurable cap on snapshots per file and a maximum age in days.
Recovery is entirely in human hands. The CLI gives you four commands and nothing else. List shows every snapshot in the vault. History shows the version timeline for a single file. Diff compares a vault snapshot against the current state on disk. Restore puts the file back where it was. Recovery takes seconds, not hours, it's a copy operation, not a reconstruction.
The agent operates at full speed. The human operator holds the undo button. Those two facts coexist because the gate draws an uncrossable line between them.
Where It Fits
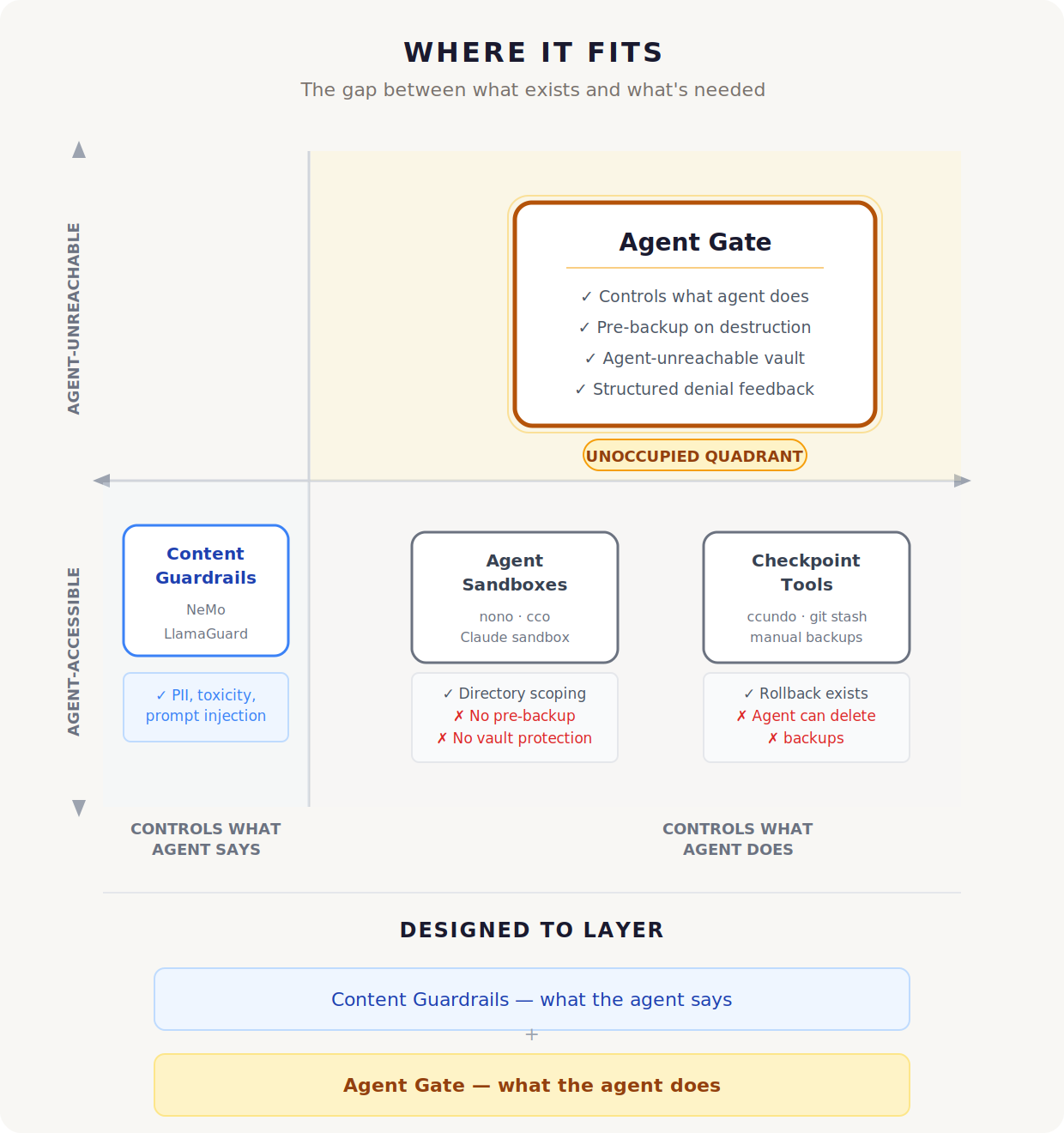
The AI safety ecosystem has two well-developed categories and a gap between them.
Content guardrails, NeMo Guardrails, LlamaGuard, Guardrails AI, solve what the LLM says. They filter outputs for toxicity, PII leakage, prompt injection, and hallucination. They're mature, effective, and solving a genuinely important problem. But they don't address what happens after the model produces a tool call and the client code executes it. A content filter can't prevent a file deletion.
Agent sandboxes and checkpoint tools address execution, but with a fundamental limitation. Sandboxes like nono and cco scope the agent to permitted directories, which is necessary but not sufficient. They don't back up files before destruction. Checkpoint tools like ccundo and git stash provide rollback, but the backups live inside the agent's reach. The agent that deletes your files can also delete the backups. The safety net is inside the blast radius.
Agent Gate occupies the quadrant where these two dimensions intersect and nobody else is building: it controls what the agent does, not just what it says, and the recovery mechanism is agent-unreachable. The vault is protected by the same gate that enforces the directory envelope. The agent cannot touch it.
This isn't a replacement for content guardrails, it's the complementary layer. Content guardrails handle the model's outputs. Agent Gate handles the model's actions. They're designed to stack. A well-defended agent has both: filtering on what it says, authority control on what it does, and a recovery path that no amount of autonomous reasoning can compromise
Technical Details
Language: Python 3.9, PyYAML — no heavy dependencies
License: Apache 2.0
Test suite: 22/22 passing
Integration: Claude Code PreToolUse hooks (live tested)
Architecture: Classifier (pure lookup) → Gate (condition evaluation, vault routing) → Vault (snapshot, manifest, retention)
Design: Prevention over auditability. Pre-computed classification. Inspect the action, not the reasoning.
Limitations
This is a safety net for well-intentioned agents making mistakes. It is not a security boundary against adversarial agents.
The Bash command parser treats all non-flag arguments as potential paths, naive but conservative
Shell expansion (`$()`, backticks, variable substitution) is not evaluated, the gate sees literal strings
Interpreter bypass (`python3 -c "os.remove()"`) is not reliably caught
This is application-layer gating, not OS-level sandboxing
The gate trusts that Claude Code routes all tool calls through the hook system
These are documented limitations, not hidden ones. The architecture is designed to be layered, Agent Gate handles authority control, and it can sit alongside OS-level sandboxing, content guardrails, and network policies for defense in depth
Roadmap
Phase 1 ✅ — Core engine with simulated tool calls (22/22 tests)
Phase 2 ✅ — Claude Code integration via PreToolUse hooks (live tested)
Phase 3 — MCP proxy (transparent protocol-level interception for any MCP-connected agent)
Phase 4 — OPA/Rego policy engine (sub-millisecond evaluation at production scale)
View the Code
The complete implementation is open source:
GitHub: SeanFDZ/agent-gate